Прощай, графика: как графические процессоры стали доминировать в области искусственного интеллекта и вычислений
Тридцать лет назад центральные процессоры и другие специализированные процессоры обрабатывали практически все вычислительные задачи. Видеокарты той эпохи помогали ускорить рисование 2D-фигур в Windows и приложениях, но не служили никакой другой цели.
Перенесемся в сегодняшний день, и увидим, что графический процессор стал одним из самых доминирующих чипов в отрасли.
Но давно прошли те времена, когда единственной функцией графического чипа была графика – по иронии судьбы – машинное обучение и высокопроизводительные вычисления в значительной степени зависят от вычислительной мощности скромного графического процессора. Присоединяйтесь к нам, и мы рассмотрим, как этот чип превратился из скромного пиксельного толкателя в пылающую электростанцию вычислений с плавающей точкой.
В начале всем правили процессоры
Давайте вернемся в конец 1990-х. Область высокопроизводительных вычислений, охватывающая научные исследования с использованием суперкомпьютеров, обработку данных на стандартных серверах и инженерные и проектные задачи на рабочих станциях, полностью опиралась на два типа ЦП: 1) специализированные процессоры, разработанные для одной цели, и 2) готовые чипы от AMD, IBM или Intel.
Суперкомпьютер ASCI Red был одним из самых мощных в 1997 году, он состоял из 9632 процессоров Intel Pentium II Overdrive (на фото ниже). Поскольку каждый блок работал на частоте 333 МГц, система могла похвастаться теоретической пиковой производительностью вычислений чуть более 3,2 TFLOPS (триллиона операций с плавающей точкой в секунду).

Поскольку в этой статье мы будем часто ссылаться на TFLOPS, стоит потратить немного времени, чтобы объяснить, что это значит. В информатике числа с плавающей точкой , или, короче, числа с плавающей точкой, — это значения данных, представляющие нецелые значения, например 6,2815 или 0,0044. Целые значения, известные как целые числа, часто используются для вычислений, необходимых для управления компьютером и любым программным обеспечением, работающим на нем.
Плавающие числа имеют решающее значение в ситуациях, где точность имеет первостепенное значение – особенно в том, что касается науки или техники. Даже простое вычисление, например, определение длины окружности, включает в себя по крайней мере одно значение с плавающей точкой.
В течение многих десятилетий центральные процессоры имели отдельные схемы для выполнения логических операций над целыми числами и числами с плавающей точкой. В случае вышеупомянутого Pentium II Overdrive он мог выполнять одну базовую операцию с плавающей точкой (умножение или сложение) за такт. Теоретически, именно поэтому ASCI Red имел пиковую производительность с плавающей точкой 9632 ЦП x 333 миллиона тактов x 1 операция/цикл = 3 207 456 миллионов FLOPS.
Эти цифры основаны на идеальных условиях (например, использование простейших инструкций по данным, которые помещаются в кэш) и редко достижимы в реальной жизни. Тем не менее, они дают хорошее представление о потенциальной мощности систем.

Другие суперкомпьютеры могли похвастаться схожим числом стандартных процессоров: Blue Pacific в Ливерморской национальной лаборатории им. Лоуренса использовал 5808 чипов IBM PowerPC 604e , а Blue Mountain в Лос-Аламосской национальной лаборатории (выше) вмещал 6144 процессора MIPS Technologies R1000 .
Чтобы достичь уровня обработки терафлоп, нужны были тысячи процессоров, все они поддерживались огромными объемами оперативной памяти и жестких дисков. Это было и остается следствием математических требований машин.
Когда мы впервые знакомимся с уравнениями в физике, химии и других предметах в школе, все одномерно. Другими словами, мы используем одно число для расстояния, скорости, массы, времени и т. д. Однако для точного моделирования и имитации явлений требуется больше измерений, и математика поднимается в область векторов , матриц и тензоров .
Они рассматриваются как отдельные сущности в математике, но включают в себя несколько значений, что подразумевает, что любой компьютер, работающий с вычислениями, должен обрабатывать многочисленные числа одновременно. Учитывая, что тогдашние процессоры могли обрабатывать только одно или два числа с плавающей точкой за цикл, их требовались тысячи.
SIMD вступает в борьбу: MMX, 3DNow! и SSE
В 1997 году Intel обновила серию процессоров Pentium с помощью технологического расширения под названием MMX — набора инструкций, которые использовали восемь дополнительных регистров внутри ядра. Каждый из них был разработан для хранения от одного до четырех целочисленных значений. Эта система позволяла процессору выполнять одну инструкцию для нескольких чисел одновременно, подход, более известный как SIMD (Single Instruction, Multiple Data).
Год спустя AMD представила собственную версию под названием 3DNow!. Она была заметно лучше, так как регистры могли хранить значения с плавающей точкой. Прошел еще год, прежде чем Intel решила эту проблему в MMX, представив SSE (Streaming SIMD Extensions) в Pentium III.

С наступлением нового тысячелетия разработчики высокопроизводительных компьютеров получили доступ к стандартным процессорам, способным эффективно обрабатывать векторную математику.
После масштабирования до тысяч эти процессоры могли одинаково хорошо управлять матрицами и тензорами. Несмотря на это достижение, мир суперкомпьютеров по-прежнему отдавал предпочтение старым или специализированным чипам, поскольку эти новые расширения не были точно разработаны для таких задач. Это также было верно для другого быстро набирающего популярность процессора, который лучше справлялся с работой SIMD, чем любой ЦП от AMD или Intel: GPU.
Это также справедливо для другого быстро набирающего популярность процессора, который лучше справляется с работой SIMD, чем любой ЦП от AMD или Intel: графического процессора.
В ранние годы графических процессоров ЦП обрабатывал вычисления для треугольников, составляющих сцену (отсюда название 3DNow!, которое AMD использовала для своей реализации SIMD). Однако раскрашивание и текстурирование пикселей обрабатывалось исключительно ГП, и многие аспекты этой работы включали векторную математику.
Лучшие потребительские видеокарты 20+ лет назад, такие как 3dfx Voodoo5 5500 и Nvidia GeForce 2 Ultra, были выдающимися устройствами SIMD. Однако они были созданы для производства 3D-графики для игр и ничего более. Даже карты на профессиональном рынке были сосредоточены исключительно на рендеринге.

ATI FireGL 3 стоимостью $2000 от ATI щеголял двумя чипами IBM (геометрическим движком GT1000 и растеризатором RC1000), огромными 128 МБ DDR-SDRAM и заявленной вычислительной мощностью в 30 ГФЛОПС. Но все это было для ускорения графики в таких программах, как 3D Studio Max и AutoCAD, с использованием API рендеринга OpenGL.
Графические процессоры той эпохи не были оснащены для других целей, поскольку процессы, лежащие в основе преобразования 3D-объектов и преобразования их в изображения на мониторе, не включали значительного количества математики с плавающей точкой. Фактически, значительная ее часть находилась на целочисленном уровне, и потребовалось несколько лет, прежде чем графические карты начали активно работать со значениями с плавающей точкой на всех своих конвейерах.
Одним из первых был процессор R300 от ATI , который имел 8 отдельных пиксельных конвейеров, обрабатывающих всю математику с точностью 24 бита с плавающей точкой. К сожалению, не было возможности использовать эту мощь для чего-либо, кроме графики — аппаратное обеспечение и соответствующее программное обеспечение были полностью ориентированы на изображение.
Инженеры-компьютерщики не забыли о том, что у графических процессоров было огромное количество SIMD-мощности, но не было способа применить ее в других областях. Удивительно, но именно игровая консоль показала, как решить эту сложную проблему.
Новая эра объединения
В ноябре 2005 года на прилавках магазинов появилась игровая приставка Xbox 360 от Microsoft. Она была оснащена центральным процессором, разработанным и произведенным IBM на основе архитектуры PowerPC, и графическим процессором, разработанным ATI и произведенным TSMC.
Этот графический чип под кодовым названием Xenos был особенным, поскольку его компоновка полностью исключала классический подход с раздельными вершинными и пиксельными конвейерами.
Xenos положил начало парадигме дизайна, которая используется и по сей день.

На их месте был трехканальный кластер массивов SIMD. В частности, каждый кластер состоял из 16 векторных процессоров, каждый из которых содержал пять математических блоков. Такая компоновка позволяла каждому массиву выполнять две последовательные инструкции из потока за цикл на 80 значениях данных с плавающей точкой одновременно.
Известный как унифицированная архитектура шейдеров , каждый массив мог обрабатывать любой тип шейдера. Несмотря на то, что другие аспекты чипа стали сложнее, Xenos зажег парадигму проектирования, которая используется и по сей день. С тактовой частотой 500 МГц весь кластер теоретически мог достичь скорости обработки 240 GFLOPS (500 x 16 x 80 x 2) для трех потоков команды умножения-затем-сложения.
Чтобы дать этой цифре некоторое представление о масштабе, некоторые из лучших суперкомпьютеров мира десятилетием ранее не могли сравниться с этой скоростью. Например, aragon XP/S140 в Sandia National Laboratories, который возглавил мировой список суперкомпьютеров в 1994 году с его 3680 процессорами Intel i860, имел пиковую производительность 184 GFLOPS. Темпы разработки чипов быстро обогнали эту машину, но то же самое можно сказать и о GPU.
Процессоры уже несколько лет включают собственные массивы SIMD — например, оригинальный Pentium MMX от Intel имел специальный блок для выполнения инструкций на векторе, охватывающий до восьми 8-битных целых чисел. К тому времени, когда Xenos от Xbox начали использовать в домах по всему миру, такие блоки как минимум удвоились в размере, но они все еще были крошечными по сравнению с блоками в Xenos.

Когда видеокарты потребительского уровня начали оснащаться графическими процессорами с унифицированной шейдерной архитектурой, они уже могли похвастаться заметно более высокой скоростью обработки, чем графический чип Xbox 360.
G80 от Nvidia (выше), используемый в GeForce 8800 GTX (2006), имел теоретический пик в 346 GLFOPS, а R600 от ATI в Radeon HD 2900 XT (2007) мог похвастаться 476 GLFOPS.
Оба производителя графических чипов быстро извлекли выгоду из этой вычислительной мощности в своих профессиональных моделях. Несмотря на непомерную цену, ATI FireGL V8650 и Nvidia Tesla C870 хорошо подходили для высокопроизводительных научных компьютеров. Однако на самом высоком уровне суперкомпьютеры во всем мире продолжали полагаться на стандартные ЦП. Фактически, прошло несколько лет, прежде чем графические процессоры начали появляться в самых мощных системах.
Но почему графические процессоры не стали использоваться сразу, если они явно обеспечивали огромную скорость обработки?
Суперкомпьютеры и подобные системы чрезвычайно дороги в проектировании, создании и эксплуатации. В течение многих лет они строились вокруг массивных массивов ЦП, поэтому интеграция еще одного процессора не была делом за одну ночь. Такие системы требовали тщательного планирования и начального мелкомасштабного тестирования перед увеличением количества чипов.
Во-вторых, заставить все эти компоненты функционировать гармонично, особенно в отношении программного обеспечения, — это немалый подвиг, что было существенным недостатком графических процессоров того времени. Хотя они стали высокопрограммируемыми, программное обеспечение, ранее доступное для них, было довольно ограниченным.
HLSL (Higher Level Shader Language) от Microsoft, библиотека Cg от Nvidia и GLSL от OpenGL упростили доступ к вычислительным возможностям графического чипа, хотя и исключительно для рендеринга.
Все изменилось с появлением графических процессоров с унифицированной шейдерной архитектурой.
В 2006 году компании ATI, которая к тому времени стала дочерней компанией AMD , и Nvidia выпустили программные инструменты, призванные раскрыть эту мощь не только для графики, с помощью своих API-интерфейсов под названием CTM (Close To Metal) и CUDA (Compute Unified Device Architecture) соответственно.
Однако научному сообществу и сообществу, занимающемуся обработкой данных, на самом деле требовался комплексный пакет, который бы рассматривал огромные массивы центральных и графических процессоров (часто называемые гетерогенной платформой) как единое целое, состоящее из множества вычислительных устройств.
Их потребность была удовлетворена в 2009 году. Первоначально разработанный Apple, OpenCL был выпущен Khronos Group, которая поглотила OpenGL несколькими годами ранее, и стал фактической программной платформой для использования графических процессоров за пределами повседневной графики или, как тогда называлась эта область, GPGPU, что означало универсальные вычисления на графических процессорах (термин, введенный Марком Харрисом) .
Графический процессор вступает в гонку вычислений
В отличие от обширного мира технических обзоров, нет сотен рецензентов по всему миру, тестирующих суперкомпьютеры на предмет их предполагаемых заявлений о производительности. Однако текущий проект, начатый в начале 1990-х годов Университетом Мангейма в Германии, стремится сделать именно это.
Группа , известная как TOP500 , дважды в год публикует рейтинг 10 самых мощных суперкомпьютеров в мире.
Первые записи с графическими процессорами появились в 2010 году, когда в Китае появились две системы — Nebulae и Tianhe-1. Они использовали чипы Tesla C2050 от Nvidia (по сути, GeForce GTX 470, как показано на рисунке ниже) и Radeon HD 4870 от AMD соответственно, причем первый мог похвастаться теоретическим пиком в 2984 TFLOPS.

В эти ранние дни высокопроизводительных GPGPU Nvidia была предпочтительным поставщиком для оснащения вычислительного монстра не из-за производительности (так как карты AMD Radeon обычно предлагали более высокую степень производительности обработки), а из-за программной поддержки. CUDA быстро развивалась, и прошло несколько лет, прежде чем у AMD появилась подходящая альтернатива, побуждающая пользователей использовать OpenCL.
Однако Nvidia не полностью доминировала на рынке, поскольку процессор Intel Xeon Phi пытался занять свое место. Возникнув из отмененного проекта GPU под названием Larrabee , эти массивные чипы были своеобразным гибридом CPU-GPU, состоящим из нескольких ядер Pentium (часть CPU) в паре с большими блоками с плавающей точкой (часть GPU).
Исследование внутренних компонентов Nvidia Tesla C2050 выявило 14 блоков, называемых потоковыми мультипроцессорами (SM), разделенных кэшем и центральным контроллером. Каждый из них включает 32 набора из двух логических схем (которые Nvidia называет ядрами CUDA), которые выполняют все математические операции — одну для целочисленных значений, а другую для чисел с плавающей точкой. В последнем случае ядра могут управлять одной операцией FMA (Fused Multiply-Add) за такт с одинарной (32-битной) точностью; операции с двойной точностью (64-битные) требуют как минимум двух тактов.
Блоки с плавающей точкой в чипе Xeon Phi (показаны ниже) выглядят несколько похожими, за исключением того, что каждое ядро обрабатывает вдвое меньше значений данных, чем SM в C2050. Тем не менее, поскольку имеется 32 повторяющихся ядра по сравнению с 14 у Tesla, один процессор Xeon Phi может обрабатывать больше значений за такт в целом. Однако первый выпуск чипа Intel был скорее прототипом и не смог полностью реализовать свой потенциал — продукт Nvidia работал быстрее, потреблял меньше энергии и в конечном итоге оказался лучше.

Это станет повторяющейся темой в трехсторонней битве GPGPU между AMD, Intel и Nvidia. Одна модель может обладать превосходным числом процессорных ядер, в то время как другая может иметь более высокую тактовую частоту или более надежную систему кэширования.
Хотя один ЦП не мог конкурировать с производительностью SIMD среднего ГП, при соединении тысячами они оказывались адекватными. Однако таким системам не хватало энергоэффективности.
Процессоры оставались необходимыми для всех типов вычислений, и многие суперкомпьютеры и высокопроизводительные вычислительные системы по-прежнему состояли из процессоров AMD или Intel. Хотя один процессор не мог конкурировать с производительностью SIMD среднего графического процессора, при соединении тысячами они оказывались адекватными. Однако таким системам не хватало энергоэффективности.
Например, в то же время, когда графический процессор Radeon HD 4870 использовался в суперкомпьютере Tianhe-1, самый большой серверный процессор AMD (12-ядерный Opteron 6176 SE ) был в ходу. При потребляемой мощности около 140 Вт, процессор теоретически мог достичь 220 GFLOPS, тогда как графический процессор предлагал пик в 1200 GFLOPS всего за дополнительные 10 Вт и за часть стоимости.
Маленькая видеокарта, которая могла бы (делать больше)
Несколько лет спустя, и не только суперкомпьютеры мира массово использовали графические процессоры для проведения параллельных вычислений . Nvidia активно продвигала свою платформу GRID , службу виртуализации графических процессоров, для научных и других приложений. Первоначально запущенная как система для хостинга облачных игр, растущий спрос на крупномасштабные, доступные GPGPU сделал этот переход неизбежным. На своей ежегодной технологической конференции GRID был представлен как важный инструмент для инженеров в различных секторах.
На том же мероприятии производитель GPU дал возможность заглянуть в будущую архитектуру под кодовым названием Volta. Было раскрыто немного подробностей, и общее предположение заключалось в том, что это будет еще один чип, обслуживающий все рынки Nvidia.

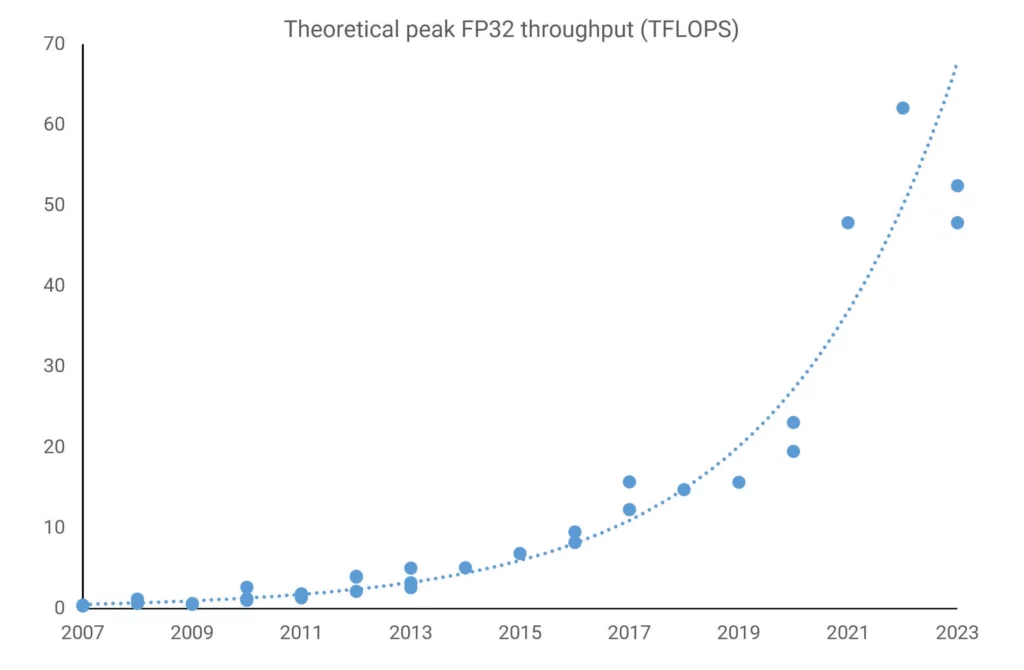
Тем временем AMD делала нечто подобное, используя свой регулярно обновляемый дизайн Graphics Core Next (GCN) в своей игровой линейке Radeon, а также в своих серверных картах FirePro и Radeon Sky. К тому времени показатели производительности были ошеломляющими — у FirePro W9100 пиковая пропускная способность FP32 составляла 5,2 TFLOPS (32-битная плавающая точка), что было бы немыслимо для суперкомпьютера менее чем за два десятилетия до этого.
Графические процессоры по-прежнему в первую очередь разрабатывались для 3D-графики, но достижения в технологиях рендеринга означали, что эти чипы должны были стать все более эффективными в обработке общих вычислительных нагрузок. Единственной проблемой была их ограниченная способность к высокоточной математике с плавающей точкой, т. е. FP64 или выше.
Если взглянуть на лучшие суперкомпьютеры 2015 года, то можно увидеть, что относительно небольшое количество из них использует графические процессоры (Xeon Phi от Intel или Tesla от Nvidia) по сравнению с теми, которые полностью базируются на центральных процессорах.
Все изменилось, когда Nvidia запустила архитектуру Pascal в 2016 году. Это была первая попытка компании разработать графический процессор исключительно для рынка высокопроизводительных вычислений, в то время как другие использовались в нескольких секторах. Только один из первых был когда-либо создан (GP100), и он породил всего 5 продуктов, но там, где все предыдущие архитектуры имели только несколько ядер FP64, этот чип вмещал почти 2000 из них.

Tesla P100 предлагала более 9 TFLOPS обработки FP32 и половину этого показателя для FP64, что делало ее действительно мощной. AMD Radeon Pro W9100, использующая чип Vega 10, была на 30% быстрее в FP32, но на 800% медленнее в FP64. К этому моменту Intel была на грани прекращения выпуска Xeon Phi из-за плохих продаж.
Год спустя Nvidia наконец выпустила Volta, сразу дав понять, что компания заинтересована не только в выводе своих графических процессоров на рынки HPC и обработки данных — она нацеливается и на другие рынки.
Нейроны, сети, о боже!
Глубокое обучение — это область в более широком наборе дисциплин, известных как машинное обучение , которое, в свою очередь, является подмножеством искусственного интеллекта. Оно подразумевает использование сложных математических моделей, известных как нейронные сети, которые извлекают информацию из заданных данных.
Примером этого является определение вероятности того, что представленное изображение изображает определенное животное. Для этого модель должна быть «обучена» — в этом примере показаны миллионы изображений этого животного, а также миллионы других, на которых животное не показано. Математика, используемая в этом случае, основана на матричных и тензорных вычислениях.
На протяжении десятилетий такие рабочие нагрузки были пригодны только для массивных суперкомпьютеров на базе CPU. Однако уже в 2000-х годах стало очевидно, что графические процессоры идеально подходят для таких задач.
Тем не менее, Nvidia сделала ставку на значительное расширение рынка глубокого обучения и добавила дополнительную функцию в свою архитектуру Volta, чтобы выделить ее в этой области. Продаваемые как тензорные ядра , они представляли собой банки логических блоков FP16, работающие вместе как большой массив, но с очень ограниченными возможностями.

Фактически, они были настолько ограничены, что выполняли только одну функцию: умножение двух матриц FP16 4×4 вместе, а затем добавление к результату еще одной матрицы FP16 или FP32 4×4 (процесс, известный как операция GEMM). Предыдущие графические процессоры Nvidia, а также процессоры конкурентов также были способны выполнять такие вычисления, но далеко не так быстро, как Volta. Единственный графический процессор, созданный с использованием этой архитектуры, GV100, содержал в общей сложности 512 тензорных ядер, каждое из которых было способно выполнять 64 GEMM за такт.
В зависимости от размера матриц в наборе данных и используемого размера плавающей точки, карта Tesla V100 теоретически могла бы достичь 125 TFLOPS в этих тензорных вычислениях. Volta была явно разработана для нишевого рынка, но там, где GP100 вошел в область суперкомпьютеров ограниченно, новые модели Tesla были быстро приняты.
Любители ПК знают, что впоследствии компания Nvidia добавила тензорные ядра в свои потребительские продукты в последующей архитектуре Turing и разработала технологию масштабирования под названием DLSS (Deep Learning Super Sampling) , которая использует ядра в графическом процессоре для запуска нейронной сети на масштабируемом изображении, исправляя любые артефакты в кадре.
На короткий период Nvidia захватила рынок глубокого обучения с ускорением на GPU, а ее подразделение центров обработки данных показало резкий рост доходов — темпы роста составили 145% в 2017 финансовом году, 133% в 2018 финансовом году и 52% в 2019 финансовом году. К концу 2019 финансового года продажи HPC, глубокого обучения и других направлений составили 2,9 млрд долларов, что стало очень позитивным результатом.
Но затем рынок действительно взорвался . Общая прибыль компании за последний квартал 2023 года составила $22,1 млрд, что на 265% больше, чем в предыдущем году. Большая часть этого роста была получена за счет инициатив компании в области искусственного интеллекта, которые принесли $18,4 млрд дохода.

Однако там, где есть деньги, конкуренция неизбежна, и хотя Nvidia по-прежнему остается ведущим поставщиком графических процессоров, другие крупные технологические компании не сидят сложа руки.
В 2018 году Google начала предлагать доступ к собственным чипам тензорной обработки, которые она разработала самостоятельно, через облачный сервис. Amazon вскоре последовала примеру со своим специализированным ЦП, AWS Graviton . Тем временем AMD реструктурировала свое подразделение GPU, сформировав две отдельные линейки продуктов: одну преимущественно для игр (RDNA), а другую исключительно для вычислений (CDNA).
В то время как RDNA заметно отличалась от своего предшественника, CDNA была во многом естественной эволюцией GCN, хотя и масштабированной до огромного уровня. Если взглянуть на сегодняшние GPU для суперкомпьютеров, серверов данных и машин ИИ, то все огромно.
MI250X от AMD на базе CDNA 2 имеет 220 вычислительных блоков, обеспечивая чуть менее 48 TFLOPS пропускной способности двойной точности FP64 и 128 ГБ памяти с высокой пропускной способностью (HBM2e), причем оба аспекта очень востребованы в приложениях HPC. Чип GH100 от Nvidia, использующий архитектуру Hopper и 576 ядер Tensor, потенциально может достичь 4000 TOPS с низкоточным числовым форматом INT8 в матричных вычислениях ИИ.
Однако у них всех есть одна общая черта: они не являются графическими процессорами.
Графический процессор Ponte Vecchio от Intel столь же огромен и содержит 100 миллиардов транзисторов, а у AMD MI300 их на 46 миллиардов больше , включая несколько микросхем ЦП, графики и памяти.
Однако у них всех есть одна общая черта: они определенно не являются графическими процессорами. Задолго до того, как Nvidia присвоила этот термин в качестве маркетингового инструмента, эта аббревиатура означала Graphics Processing Unit (графический процессор). У AMD MI250X вообще нет блоков вывода рендеринга (ROP), и даже GH100 обладает производительностью Direct3D только на уровне GeForce GTX 1050, что делает «G» в GPU неуместным.
Так как же мы могли бы их назвать?
«GPGPU» неидеально, так как это неуклюжая фраза, относящаяся к использованию GPU в обобщенных вычислениях, а не к самому устройству. «HPCU» (High Performance Computing Unit) не намного лучше. Но, возможно, это не так уж и важно.
В конце концов, термин «ЦП» невероятно широк и охватывает широкий спектр различных процессоров и применений.
Что дальше предстоит покорить GPU?
Учитывая миллиарды долларов, вложенные в исследования и разработки графических процессоров компаниями Nvidia, AMD, Apple, Intel и десятками других, современный графический процессор вряд ли будет заменен чем-то кардинально новым в ближайшее время.
Что касается рендеринга, то новейшие API и программные пакеты, которые их используют (например, игровые движки и приложения САПР), как правило, не зависят от оборудования, на котором выполняется код, поэтому теоретически их можно адаптировать к чему-то совершенно новому.
В графическом процессоре относительно немного компонентов, предназначенных исключительно для графики… остальное по сути представляет собой массивно-параллельный чип SIMD, поддерживаемый надежной и сложной системой памяти.
Однако в GPU относительно немного компонентов, предназначенных исключительно для графики – наиболее очевидными являются движок настройки треугольников и ROP, а блоки трассировки лучей в более поздних выпусках также являются узкоспециализированными. Однако остальное по сути представляет собой массивно-параллельный чип SIMD, поддерживаемый надежной и сложной системой памяти/кэша.
Базовые конструкции настолько хороши, насколько это вообще возможно, и любые будущие улучшения просто привязаны к достижениям в технологиях производства полупроводников. Другими словами, они могут улучшиться только за счет размещения большего количества логических блоков, работы на более высокой тактовой частоте или комбинации того и другого.
Конечно, они могут иметь новые функции, которые позволят им функционировать в более широком диапазоне сценариев. Это случалось несколько раз на протяжении всей истории GPU, хотя переход к унифицированной архитектуре шейдеров был особенно значимым. Хотя предпочтительнее иметь выделенное оборудование для обработки тензоров или вычислений трассировки лучей, ядро современного GPU способно управлять всем этим, хотя и медленнее.
Вот почему такие чипы, как AMD MI250 и Nvidia GH100, имеют сильное сходство с их аналогами для настольных ПК, и будущие разработки, предназначенные для использования в HPC и AI, вероятно, будут следовать этой тенденции. Так что если сами чипы не будут существенно меняться, что насчет их применения?

Учитывая, что все, что связано с ИИ, по сути является отраслью вычислений, GPU, скорее всего, будет использоваться всякий раз, когда необходимо выполнить множество SIMD-вычислений. Хотя в науке и технике не так много секторов, где такие процессоры еще не используются, мы, скорее всего, увидим всплеск использования производных от GPU.
В настоящее время можно приобрести телефоны, оснащенные миниатюрными чипами, единственной функцией которых является ускорение тензорных вычислений. Поскольку инструменты вроде ChatGPT продолжают расти в мощности и популярности, мы увидим больше устройств с таким оборудованием.
Скромный графический процессор превратился из устройства, предназначенного исключительно для запуска игр быстрее, чем это мог бы сделать центральный процессор, в универсальный ускоритель, обеспечивающий работу рабочих станций, серверов и суперкомпьютеров по всему миру.
Скромный графический процессор превратился из устройства, предназначенного исключительно для запуска игр быстрее, чем это мог бы сделать центральный процессор, в универсальный ускоритель, обеспечивающий работу рабочих станций, серверов и суперкомпьютеров по всему миру.
Миллионы людей по всему миру используют его каждый день — не только в наших компьютерах, телефонах, телевизорах и потоковых устройствах, но и когда мы используем сервисы, включающие распознавание голоса и изображений или предоставляющие рекомендации по музыке и видео.
Дальнейшие перспективы графических процессоров, возможно, пока неизведанные, но одно можно сказать наверняка: графический процессор останется доминирующим инструментом для вычислений и искусственного интеллекта еще на многие десятилетия вперед.



